





















- Details
- Geschrieben von: Moritz Conjé
- Kategorie: Work-Life-Flow
- Zugriffe: 10
Seit einiger Zeit betreibe ich zu Hause ein eigenes kleines Rechenzentrum: mehrere Mini-PCs, ein Netzwerkspeicher und darauf verteilt eine wachsende Zahl an Diensten, die ich selbst einrichte, pflege und weiterentwickle. Diesen Beitrag verstehe ich als Auftakt einer Serie. Bevor ich in kommenden Artikeln auf einzelne Projekte eingehe, will ich hier erst einmal den Überblick schaffen: Wie sieht mein Homelab aktuell aus, welche Hardware steckt dahinter, und welche Dienste laufen bereits produktiv.
Wie ich zu diesem Thema gekommen bin
Der Ausgangspunkt war ein einfacher Wunsch: Lösungen selbst hosten, statt mich auf fertige Cloud-Angebote zu verlassen. Eigene Infrastruktur bedeutet, dass ich entscheide, wo meine Daten liegen, wie ein Dienst konfiguriert ist und wann ich ihn erweitere. Dieser Gedanke der digitalen Unabhängigkeit hat mich schnell gepackt, und aus einem einzelnen Mini-PC ist inzwischen eine kleine, aber ernstzunehmende Infrastruktur geworden.
Was mich am Thema besonders reizt, ist die Kombination aus Planung und Umsetzung. Jeder neue Dienst beginnt mit einer Recherche- und Entscheidungsphase (Welche Software passt? Welche Hardware brauche ich? Wie hängt das mit bestehenden Diensten zusammen?), gefolgt von der eigentlichen Einrichtung, die nicht immer reibungslos verläuft. Genau in dieser Mischung aus Planungsaufwand und technischer Handarbeit liegt für mich der Reiz. Es ist ein Hobby, bei dem ich etwas Produktives erschaffe, das mir im Alltag tatsächlich einen Mehrwert bringt, statt nur ein Selbstzweck zu sein.
Nach einer mitunter herausfordernden Einrichtung stellt sich regelmäßig ein Erfolgsgefühl ein, wenn ein Dienst zuverlässig läuft und sich in meinen Alltag einfügt. Besonders interessant wird es, wenn einzelne Dienste beginnen, zusammenzuspielen. Ein Netzwerkspeicher, der von mehreren Anwendungen gleichzeitig genutzt wird, oder ein zentraler Zugriffspunkt, über den mehrere Dienste von außen erreichbar sind, sind Beispiele für solche Synergien, die den Gesamtnutzen der Infrastruktur über die Summe der Einzeldienste hinaus steigern.
Die Hardware: drei Mini-PCs und ein Netzwerkspeicher
Das Fundament meines Homelabs bilden aktuell drei Mini-PCs (NUCs), die unterschiedliche Rollen übernehmen:
- Hauptserver (ASUS NUC 15 Pro): Das leistungsstärkste Gerät und Kern der Infrastruktur. Darauf läuft Proxmox VE als Hypervisor, also die Software-Schicht, die es erlaubt, mehrere virtuelle Maschinen und Container gleichzeitig auf einer einzigen physischen Maschine zu betreiben. Fast alle produktiven Dienste sind hier als eigene VM oder als Container (LXC) organisiert.
- Zweiter NUC (Intel NUCi5, meine "erste Maschine"): Der Einstieg in dieses Hobby, derzeit "Out-of-Service", doch bereits für neue Aufgaben verplant.
- Dritter Mini-PC (GMKtec NucBox G11): Ein flexibel einsetzbares Gerät, das aktuell die Aufgaben des Intel NUCi5 zugewiesen bekommen hat.
Ergänzt wird das Ganze durch TrueNAS, meinen zentralen Netzwerkspeicher. Er läuft als eigene virtuelle Maschine auf dem Hauptserver und stellt über das Netzwerk einen Datei-Share bereit, auf den mehrere Dienste zugreifen. Das ist ein gutes Beispiel für die oben erwähnten Synergien: Statt Daten mehrfach vorzuhalten, greifen unterschiedliche Anwendungen auf einen gemeinsamen Speicherort zu.
Drei Geräte statt eines einzigen leistungsstarken Rechners, das war keine Entscheidung am Reißbrett, sondern das Ergebnis eines organischen Wachstums. Jeder Mini-PC kam zu einem Zeitpunkt dazu, an dem der vorhandene Bestand an seine Grenzen stieß oder ein neues Projekt eine eigene, isolierte Umgebung sinnvoll erscheinen ließ. So bleibt jedes Gerät überschaubar wartbar, und ein Ausfall oder Experiment auf einer Maschine gefährdet nicht automatisch die übrigen Dienste.
Welche Dienste wo laufen
Auf dem Hauptserver (Asus 15 Pro) ist inzwischen ein ganzes Bündel an Diensten zusammengekommen. Über Dockge, eine Oberfläche zur Verwaltung von Docker-Containern, betreibe ich unter anderem:
- Plex als Mediathek für Filme und Serien
- PegaProx, ein Dashboard zur Verwaltung mehrerer Proxmox-Cluster im Überblick
- Nginx Proxy Manager als zentralen Reverse Proxy, über den alle nach außen erreichbaren Dienste laufen
- Homarr als Startseite/Dashboard für alle Anwendungen
- Portainer zur zusätzlichen Container-Verwaltung
- RustDesk für den Fernzugriff
Direkt daneben laufen als eigenständige virtuelle Maschinen oder Container:
- Paperless-ngx zur digitalen Dokumentenverwaltung
- Apache Superset für ein selbst gebautes Finanz-Dashboard
- Vaultwarden als self-hosted Passwortmanager
- WireGuard als VPN-Lösung, mit der ich von unterwegs ins heimische Netzwerk gelange
Ein weiterer Container betreibt zudem einen Remote-Zugang, über den ich Programmier- und Automatisierungsaufgaben direkt im Homelab ausführen kann.
Der zweite NUC (Intel Core i5), meine "erste Maschine", war zwischenzeitlich dem Thema Smart Home gewidmet: Hier lief Home Assistant - siehe diesen Beitrag - das Herzstück meiner Haussteuerung, über das ich Sensoren, Automatisierungen und smarte Geräte zentral verwalte. Mittlerweile ist diese Anwendung jedoch auf das dritte Geräte umgezogen und die Maschine ist als ProxMox-Backup-Server eingeplant.
Der dritte Mini-PC, der GMKtec NucBox G11, hat in der bisherigen Geschichte meines Homelabs schon mehrere Rollen übernommen und agiert derzeit als neue Heimat für mein Home Assistent System. Auf einer weiteren Dockge Instanz betreibe ich eine InfluxDB und Grafana, über die ich die Daten der Sensoren speichere und für Auswertungen verwende.
Ein Blick nach vorn
Dieser Überblick ist bewusst allgemein gehalten. In den kommenden Beiträgen dieser Serie werde ich einzelne Projekte im Detail vorstellen, unter anderem:
- Nutzung des TrueNAS-Systems
- Aufbau und Härtung des eigenen Passwortmanagers mit Vaultwarden
- Details zum Auf- und Ausbau meiner Haussteuerung rund um Home Assistant
- Der zentrale Zugriffspunkt über Nginx Proxy Manager und WireGuard
Die Einrichtung des Finanz-Dashboards mit Apache Superset habe ich bereits hier erläutert.
Wo es passt, werde ich an dieser Stelle auf weitere Einzelartikel verlinken, sobald sie veröffentlicht sind.
Fazit
Aus einem einzelnen Mini-PC ist über die Zeit eine kleine, aber vielseitige Infrastruktur mit drei Geräten und einem guten Dutzend produktiver Dienste geworden. Was als technische Spielerei begann, hat sich zu einem festen Hobby entwickelt, das mir echten Mehrwert im Alltag bringt, sei es bei der Dokumentenverwaltung, der Haussteuerung oder dem Überblick über die eigenen Finanzen. Genau dieser Doppelcharakter, technisches Interesse auf der einen und spürbarer Alltagsnutzen auf der anderen Seite, macht für mich den Reiz aus. In den nächsten Beiträgen dieser Serie gehe ich tiefer in einzelne Projekte und Umsetzungen hinein.

- Details
- Geschrieben von: Moritz Conjé
- Kategorie: Work-Life-Flow
- Zugriffe: 566
Wer viel sammelt, kennt das Problem: Über Wochen und Monate häufen sich Artikel, Videos, Notizen zu einem Thema an. Sie liegen in deinem Second Brain; gut organisiert nach Tags und Kategorien. Aber irgendwann fragst du dich:
- Was habe ich da eigentlich alles?
- Und könnte ich daraus etwas machen?
Genau hier setzt dieser Artikel an. Ich zeige dir, wie Claude AI zum Kurator deiner Sammlung wird; nicht um deine Arbeit zu machen, sondern um Muster zu erkennen, die du nicht siehst. Aus chaotischen Inputs entsteht ein kohärenter Redaktionsplan. Aus einer Datenhalde wird Publishing-Struktur.
Die Pointe: Du musst dein System nicht neu aufbauen. Du bringst nur das zum Leben, was du ohnehin sammelst.
Der Moment, in dem die Fragmentierung klickte
Vor einigen Wochen saß ich vor einer klassischen Homo Creator Situation: einer Idee im Browser, einer Recherche auf YouTube, Notizen aus einem Gespräch und einer PDF-Datei, die ich noch lesen musste. Nicht Prokrastination; sondern Kontext-Fragmentierung. Mein Gedankenprozess war nicht faul, er war nur über mehrere Systeme verteilt.
Das Dilemma als reflektierter Praktiker: Ich gestalte gerne meine Werkzeuge, aber ich will nicht mehr Zeit mit der Verwaltung dieser Werkzeuge verbringen als mit der eigentlichen Arbeit.
Die Lösung liegt nicht in neuer Technologie, sondern in einer intelligenten Verbindung bestehender Systeme. In meinem Fall: Notion als Second Brain + Claude AI als Thinking Partner.
Warum Notion + Claude AI für den Homo Creator?
Das Kernproblem: Externe Intelligenz ohne Kontext
Die meisten KI-Tools arbeiten isoliert:
- ChatGPT/Claude verstehen nicht, was in deinem Notion-System passiert
- Notion ist ein fantastischer Speicher, aber kein denkender Partner
- Du fragst ChatGPT etwas, bekommst eine Antwort, musst das Ergebnis selbst in Notion eintragen
- Dein Workflow ist nicht integriert; es sind separate Inseln
Homo Creator Problem: Du brauchst ein System, das:
- deine Gedanken speichert (Notion)
- sie intelligent verarbeitet (Claude AI)
- die Ergebnisse wieder in dein System zurückführt (manuelle Integration, aber mit Struktur)
- dir Zeit für Gestaltung lässt, nicht für Verwaltung
Warum dieses Duo funktioniert
Notion ist dein strukturiertes Gedächtnis: Basierend auf der Second Brain Philosophie von Tiago Forte, habe ich bereits ein 3-Ebenen System aufgebaut, das ich in mehreren Beiträgen dokumentiert habe.
- Ebene 1 (Input): Alle Informationen, die ich sammle
- Ebene 2 (Processing): Transformation in konkrete Aufgaben und Notizen
- Ebene 3 (Output): Verdichtete, nutzbare Information
Claude AI ist dein intelligenter Co-Denker: Claude versteht Kontext, kann komplexe Gedanken zerlegen und dir helfen, chaotische Inputs in strukturierte Outputs zu verwandeln, ohne dabei dein System zu verstehen.
Die Verbindung ist das Geheimnis: Claude macht die strukturelle kognitive Arbeit (Strukturierung, Zerlegung, Denken), während du dich auf die kreative Arbeit konzentrierst (Entscheidung, Gestaltung, Anwendung).
Die bestehende Second Brain Struktur
Ich habe bereits ausführlich beschrieben, wie mein Notion-System aufgebaut ist:
Ebene 1: Input
- "Input Notes" für Web-Inhalte (Artikel, Videos, Links) mit automatischem Web-Scraping
- "Bücher DB" für Lesestoff und Notizen
- Vollständige Details: Ebene 1 - Input / Second Brain Ansatz
Ebene 2: Processing
- "Aufgaben/Tasks" Datenbank mit Kanban-Board
- Spalten: Backlog → To-Do → Doing → Follow Up → Done → Archive
- Vollständige Details: Ebene 2 - Planung und Weiterverarbeitung
Ebene 3: Output
- Verdichtete Wissensspeicher, sortiert nach Fokusfeldern
- Reife Informationen für direkte Anwendung
An dieser Stelle möchte ich nicht die Struktur neu erklären, sondern zeigen, wo und wie Claude AI sinnvoll eingreift.
Claude AI im Second Brain System
Wo Claude seinen Platz hat
Claude wird nicht zum Ersetzen von Notion, sondern zum Kurator deines Second Brains.
Die wahre Stärke liegt nicht in der Transformation einzelner Inputs, sondern darin, dass Claude dir hilft, Muster zu erkennen, Überschneidungen zu finden und daraus Struktur zu machen.
Der zentrale Use Case: Content Curation & Redaktionsplanung
Situation: Du hast über Wochen oder Monate Artikel, Videos, Notizen zu einem Themenfeld gesammelt; sagen wir "KI & Produktivität". Sie liegen in verschiedenen "Input Notes" Einträgen, mit Tags, aber ohne echte Struktur. Irgendwann fragst du dich: "Was habe ich da eigentlich alles gesammelt? Und könnte ich daraus eine Blog-Serie machen?"
Genau hier kommt Claude als Kurator ins Spiel.
Anweisung an Claude:
Ich habe folgende Einträge in meinem Second Brain zu "KI & Produktivität" gesammelt:
- Connecting to Notion MCP - Notion Docs
Fokus: Notion + Claude Integration
Meine Notiz: "ChatGPT vs Claude für Produktivität" - 12 Prompting Techniken für bessere Ergebnisse in der Arbeit mit LLMs
Fokus: Prompt Engineering
Meine Notiz: "Praktische Prompting-Techniken" - Organisiere dein digitales Leben mit der PARA-Methode
Fokus: Arbeitsweise mit dem Second Brain
Meine Notiz: "PARA Methode erklärt"
ggf. Ergänzung weitere 10-15 Einträge
Aufgabe oder Prompt an Claude:
- Fasse zusammen, was ich [in Kategorie X] gesammelt habe.
- Welche Themen-Überschneidungen siehst du?
- Könnten diese Einträge eine Blog-Serie bilden?
- Wie würde ein Redaktionsplan aussehen?
- Wie verknüpfe ich die einzelnen Beiträge sinnvoll?
Claude antwortet als Kurator:
Deine Sammlung lässt sich in 3 zusammenhängende Serien strukturieren:
- SERIE 1: Grundlagen (3 Artikel)
- "Second Brain verstehen: Die Architektur"
- Quelle: Artikel C + Video B (Intro-Teil)
- Verknüpfung: Erklärt die Theorie, auf die Serie 2 aufbaut
- "Notion für dein Second Brain: Praktische Struktur"
- Quellen: Artikel A + Video xyz
- Verknüpfung: Zeigt die Umsetzung der Architektur
- "Prompt Engineering: Denken mit Claude"
- Quellen: Video B + Artikel xyz
- Verknüpfung: Wie KI in diese Struktur passt
- SERIE 2: Integration (2-3 Artikel)
- "Claude als Kurator: Von Chaos zum Redaktionsplan"
- "Content-Planung: Wie deine Sammlung zur Serie wird"
Daraus kann folgender Redaktionsplan abgeleitet werden:
- Woche 1-2: Serie 1, Artikel 1 (Grundlagen)
- Woche 3-4: Serie 1, Artikel 2 (Notion Struktur)
- Woche 5: Serie 1, Artikel 3 (Claude Integration)
- Woche 6-7: Serie 2 (Curation & Planning)
Praktische Integration: Der Workflow
Das Kurations-Modell passt perfekt in dein Second Brain, weil es in den natürlichen Rhythmus deiner Arbeit eingreift:
Im Alltag (kontinuierlich)
- Du sammelst Inputs wie gewohnt in Notion Ebene 1
- Tags, Notizen, Links (alles wie immer)
Wöchentlich oder monatlich (30 Minuten)
- Öffne Notion → "Input Notes" Datenbank
- Filtere nach einer Kategorie/Tag (z.B. "KI & Produktivität")
- Copy-paste die gefilterten Einträge zu Claude mit der Anfrage zur Kuration (siehe Use Case oben)
- Claude liefert dir einen Redaktionsplan
- Du entscheidest: Passt diese Struktur? Welche Artikel schreibe ich zuerst?
- Los geht's mit dem Schreiben
Das Schöne daran:
- Deine Sammlung wird nicht zur toten Datenhalde
- Du brauchst nicht zu entscheiden, "was damit anfangen?" - Claude hilft dir
- Aus chaotischen Inputs entsteht ein kohärenter Redaktionsplan
- Jeder Artikel hat die komplette Quellenlandschaft dahinter
Custom Instructions für Claude (als Kurator)
Wenn du Claude als Kurator deines Second Brains nutzen möchtest, braucht Claude präzise Anweisungen.
Bei sich wiederholenden und gleichartigen Aufgaben, lohnt es sich, Zeit in ein Grundgerüst zu investieren und die verschiedenen Aspekte der Aufgabe näher zu beschreiben. Hier angedeutet mit verschiednen MD (Markdown-Dateien), die alle eine spezifischen Aspekt der Aufgabe abbilden (Format.md, Einschränkung.md, Stil.md). Ein Artikel zu der Struktur dieser Dateien folgt ggf. noch, da sich diese noch in der stetigen Entwicklung befindet.
Diese können in einer zentralen CLAUDE.md verlinkt werden. Außerdem empfiehlt sich die Nutzung einer MEMORY.md-Datei, in der anhand der konkreten Beispiele stetig gelernt wird.
Claude ist der Kurator des Second Brain Systems.
Das System:
- Ich sammle Inputs (Artikel, Videos, Notizen) in Notion Ebene 1
- Ich tagge diese nach Kategorien/Fokusfeldern
- Ich brauche Hilfe, diese Sammlung in kohärente Blog-Serien zu verwandeln
Meine Aufgabe an Claude:
Ich gebe dir eine Liste von gesammelten Inputs zu einem Thema:
- Zusammenfassen: Was habe ich über dieses Thema eigentlich gesammelt?
- Überschneidungen finden: Welche Artikel/Videos passen zusammen?
- Narrative erkennen: Könnte ich daraus eine Serie machen? In welcher Reihenfolge?
- Redaktionsplan erstellen:
- Wie viele Artikel würde ich schreiben?
- Was wäre die Reihenfolge?
- Wie verknüpfe ich sie logisch?
- Quellenlandschaft zeigen: Welche Inputs gehören zu welchem Artikel?
Output Format / Format.md:
- Klare Serien-Struktur
- Titel des Beitrages (können wir noch ändern)
- Reihenfolge mit Begründung
- Verlinkung zwischen Artikeln
- Welche Quellen ich für jeden Artikel nutze
Einschränkungen / Einschränkung.md:
- Kurz und präzise
- Fokus auf Struktur, nicht auf Schreib-Tipps
- Gib mir Optionen, aber sag nicht "Schreib jetzt Artikel XYZ"
Schreibstil / Stil.md:
- Konkrete Beispiele statt Theorie
- Nummeriert/strukturiert
- Max 300-400 Wörter pro Antwort
Warum das funktioniert
Für mich als Homo Creator funktioniert das, weil ich Technologie produktiver nutze.
Claude agiert dabei als Kurator, weil:
- Claude sieht Muster, die du nicht siehst: Wenn du 50 Inputs zu einem Thema gesammelt hast, verlierst du die Übersicht. Claude schaut drauf und sieht sofort: "Das sind eigentlich 3 zusammenhängende Serien."
- Du brauchst nicht zu spekulieren: Statt dich zu fragen "Sollte ich da einen Artikel schreiben?", hast du einen konkreten Redaktionsplan.
- Deine Sammlung wird lebendige Arbeit: Das Second Brain ist nicht mehr nur eine Datenhalde, in die du Zeug reinwirfst. Es wird zur Quelle deiner nächsten Beiträge.
- Du behältst die volle Kontrolle: Claude gibt Struktur-Vorschläge. Du entscheidest: Passt das? Änderst du es ab? Schreibst du diese Serie überhaupt?
Der subtile Effekt
Das beste an diesem Setup: Du externalisierst die Organisationsarbeit, nicht die Entscheidung.
Dein Gehirn konzentriert sich auf das, das wirklich zählt:
- Welche Struktur passt zu meinen Lesern?
- In welcher Reihenfolge erzähle ich die beste Geschichte?
- Welche Verknüpfungen schreibe ich noch hin?
Fazit
Die derzeit verfügbare KI lässt sich sehr gut nutzen, um verschiedene Wissensdatensätze und Informationsquellen zu vernetzen und zu kuratieren. Sie erweckt bestehende Sammlungen zum Leben und schafft einen konkreten Kontext, den wir selbst häufig nur intutiv wahrnehmen.
Die KI hat die Kapazität genau nach diesen Themen und Inhalten zu suchen, für die wir im Alltag keine Zeit haben, um sie uns zu einem gewünschten Zeitpunkt zu präsentieren, an dem wir uns damit beschäftigen wollen.
Der Vorteil bei einem selbstständigen KI-System, es können unabhängig vom Betreiber weitere Informationsquellen verknüpft werden; du bist nicht auf den Notion-KI-Assistenten beschränkt.
Foto von Matúš Gocman auf Unsplash

- Details
- Geschrieben von: Moritz Conjé
- Kategorie: Work-Life-Flow
- Zugriffe: 566
Wer seine Ausgaben wirklich verstehen will, braucht mehr als eine Excel-Tabelle. Ich habe Apache Superset lokal aufgesetzt – und mit etwas KI-Unterstützung ein Sankey-Diagramm gebaut, das meine Finanzen in vier Ebenen visualisiert.
Warum überhaupt ein eigenes Dashboard?
Banking-Apps zeigen Kontostände. Was sie selten zeigen: wohin das Geld wirklich fließt, wenn man die Ausgaben in sinnvolle Kategorien aufdröselt. Ich wollte das ändern – ohne meine Daten an einen Cloud-Dienst zu übergeben. Die Lösung: Apache Superset, eine Open-Source-Plattform für Datenvisualisierung, die sich vollständig selbst hosten lässt.
Apache Superset – was ist das?
Apache Superset ist ein quelloffenes Business-Intelligence-Tool, das ursprünglich bei Airbnb entwickelt wurde. Es unterstützt Dutzende Datenquellen, erlaubt komplexe SQL-Abfragen und bietet eine breite Bibliothek an Chart-Typen – darunter auch das Sankey-Diagramm, das für Geldflüsse wie gemacht ist.
Der entscheidende Vorteil gegenüber kommerziellen Alternativen wie Tableau oder Looker: alles bleibt lokal. Die Daten liegen auf dem eigenen Rechner, in einem Docker-Container – kein Dritter hat Zugriff.
Installation per Docker
Superset lässt sich über das offizielle Docker-Compose-Setup einrichten. Wer schon einmal einen Dienst per Docker gestartet hat, findet sich schnell zurecht. Die grundlegenden Schritte: Repository klonen, Umgebungsvariablen anpassen, Container starten.
Hinweis: Beim ersten Start kann es zu Konfigurationsproblemen kommen – etwa mit Datenbank-Migrationen oder fehlenden Umgebungsvariablen. Hier lohnt es sich, die Container-Logs genau zu lesen (docker compose logs -f).Genau an dieser Stelle kam Claude ins Spiel. Ich hatte einen Fehler beim Start, der nicht auf Anhieb verständlich war. Ich habe Claude daraufhin Zugriff auf den Installationspfad gegeben – und die KI hat nicht nur die Ursache erklärt, sondern auch den korrekten Fix geliefert. Ein iterativer Prozess, der am Ende funktioniert hat.
Die KI wurde zum Debugging-Partner: Zugriff auf das lokale Projekt, Anweisungen abwarten, Lösung anwenden – und wieder von vorne, bis der Container sauber lief.
Daten importieren: von der CSV zur Datenbank
Meine Ausgangsdaten waren Kontoauszüge im CSV-Format – so wie sie jede Bank zum Download anbietet. Das Problem: Die Spaltenstruktur und das Datumsformat variieren je nach Bank, und Superset erwartet eine saubere Tabelle in einer Datenbank.
Mit Claude habe ich die passenden SQL-Befehle generiert, um die CSV-Daten zu importieren und dabei gleichzeitig zu bereinigen. Konkret:
- CSV-Struktur analysieren und Zieltabelle in SQLite anlegen
- Datumsfelder normalisieren, Beträge als numerische Werte importieren
- Kategorien und Unterkategorien als eigene Spalten hinzufügen
- Dataset in Superset registrieren und für Charts freigeben
Wer seine Ausgaben kategorisieren will, kommt um eine manuelle Zuordnung nicht ganz herum – zumindest einmalig. Ich habe dafür eine einfache Mapping-Tabelle angelegt, die Buchungstext-Muster einer Kategorie zuweist.
Das Sankey-Diagramm – vier Ebenen für den Geldfluss
Das Herzstück des Dashboards ist ein Sankey-Diagramm. Es visualisiert, wie Geld von einer Quelle durch mehrere Stufen fließt – ideal für Finanzdaten. Mein Aufbau umfasst vier Ebenen:
- Ebene 1 – Einkommen: Der Ausgangspunkt. Alle Geldeingänge fließen hier zusammen.
- Ebene 2 – Hauptkategorie: Wohnen, Lebenshaltung, Freizeit, Sparen – die groben Ausgabenblöcke.
- Ebene 3 – Unterkategorie: Miete, Nebenkosten, Lebensmittel, Gastronomie, Kultur, Sport und weitere.
- Ebene 4 – Zweck: Die konkrete Buchungsebene – Supermarkt, Fitnessstudio, Streamingdienst, Restaurantbesuch.
Was auf den ersten Blick abstrakt klingt, wird im Diagramm unmittelbar anschaulich: Man sieht auf einen Blick, wie viel vom Gesamteinkommen in die Hauptkategorien fließt, wie sich diese auf Unterkategorien aufteilen und für welche konkreten Zwecke das Geld letztlich ausgegeben wird.
Dashboard: weitere Kennzahlen, Diagramme, Filter
Weitere Diagramme kann man in einem Dashboard zusammenfassend darstellen.
Neben dem Sankey-Diagramm gebe ich mir feste Kennzahlen aus:
- Einnahmen
- Ausgaben
- Differenz
- Sparrate (Betrag)
- Sparquote (%)
Durch die Kategorisierung in den Kontoauszügen werden diese ganz einfach automatisch ausgerechnet und angezeigt.
Das Dashboard wird ergänzt durch Filter, in meinem Fall nach Monaten, also 01/2026, 02/2026 und so weiter. Durch diese Monatsauswahl kann man die Monate untereinander vergleichen und Auffälligkeiten ins nachvollziehbar.
Außerdem können mehrere Monate (oder das ganze Jahr) zusammengefasst werden. Alles im selben Dashboard.
KI als Werkzeug – nicht als Abkürzung
Ein Aspekt, der mir bei diesem Projekt wichtig erscheint: Die KI hat die Arbeit nicht ersetzt, sondern qualitativ verändert. Ich musste weiterhin verstehen, was ich tue – welche SQL-Struktur Sinn ergibt, wie Superset Datasets aufbaut, was ein Sankey-Diagramm an Datenstruktur erwartet.
Aber anstatt mich durch Dokumentationsseiten zu kämpfen oder Trial-and-Error bei SQL-Queries zu betreiben, hatte ich einen Gesprächspartner, der Fehler erklärt, Alternativen vorschlägt und Code direkt lieferbar macht. Das beschleunigt nicht nur – es senkt die Hemmschwelle, solche Projekte überhaupt anzugehen.
Fazit: Eigenes Finanz-Dashboard ist möglich
Apache Superset, Docker und ein wenig KI-Unterstützung reichen aus, um ein vollwertiges Finanz-Dashboard auf dem eigenen Rechner zu betreiben. Die Daten bleiben lokal, die Visualisierung ist flexibel, und der Aufbau ist – mit der richtigen Unterstützung – auch ohne tiefes Datenbankwissen machbar.
Das Sankey-Diagramm mit vier Ebenen ist für mich inzwischen das wichtigste Werkzeug für den monatlichen Finanzüberblick. Wer ähnliche Ausgaben-Strukturen kennt und seine Daten endlich sinnvoll visualisieren möchte, findet in diesem Setup einen guten Startpunkt.

- Details
- Geschrieben von: Moritz Conjé
- Kategorie: Work-Life-Flow
- Zugriffe: 552
Einleitung: Das Problem der Papierlast
Dokumente sammeln sich an. Steuererklärungen, Verträge, Rechnungen, Quittungen, Behördenschreiben. Manche liegen noch auf meinem Schreibtisch von vor einem Jahr. Andere sind in Ordnern archiviert, aber wo genau?
Das digitale Chaos ist ähnlich schlimm. PDFs landen im Download-Ordner, in verschiedenen Cloud-Speichern, überall verteilt. Wenn ich später eine Rechnung brauche oder einen Vertrag suche, brauche ich zu lange, um sie zu finden.
Das war lange mein Standard. Bis ich anfing, mich zu fragen: Wie kann ich meine Dokumente wirklich organisiert halten? Nicht nur abspeichern, sondern durchsuchbar machen. Mit Schlagworten versehen. Nach Kategorien gruppieren.
Die Lösung, die ich gesucht habe: Ein System, das automatisch digitalisiert, das Volltextsuche bietet, das mit wenig Aufwand funktioniert.
Das System heißt Paperless-ngx.
Warum Paperless-ngx (und nicht die Alternativen)?
Es gibt viele Lösungen für Dokumentenverwaltung. Google Drive, Dropbox, kommerzielle DMS-Systeme wie DocuWare. Warum habe ich mich für Paperless-ngx entschieden?
Drei Gründe:
1. Open Source: Der Code ist öffentlich
Bei kommerziellen Lösungen weiß ich nicht, was mit meinen Dokumenten passiert. Wo werden sie gespeichert? Wer hat Zugriff? Bei Open Source kann ich den Code selbst ansehen. Ich vertraue nicht blind; ich verstehe, wie das System funktioniert.
2. Self-Hosted: Meine Daten bleiben bei mir
Cloud-Lösungen sind bequem. Aber meine Steuerdokumente, meine Verträge; die möchte ich nicht auf fremde Server hochladen. Mit Paperless-ngx läuft alles auf meinem eigenen NUC zu Hause. Meine Daten, meine Kontrolle.
3. Kostenlos: Keine Abo-Gebühren
Kommerzielle DMS-Systeme kosten Geld. Monatlich oder jährlich. Paperless-ngx ist kostenlos. Ich zahle nur für die Hardware, die ich ohnehin für andere Projekte nutze - wie dem Smart Home System aus meinem letzten Artikel.
Was Paperless-ngx nicht ist
Ein wichtiger Punkt: Es ist nicht ein Ersatz für eine Buchführungs-Software. Es speichert Dokumente und macht sie auffindbar - es ersetzt nicht das Tracking von Ausgaben oder die Rechnungsverwaltung in anderen Tools.
Es ist auch nicht vollautomatisch. Der Großteil läuft automatisch (OCR, Tagging), aber manchmal muss ich manuell eingreifen und Schlagworte setzen. Das ist aber nicht kompliziert, es dauert Sekunden.
Hardware und Infrastruktur
Paperless-ngx braucht eine Grundlage. Ein System, auf dem es läuft.
Wie im Artikel über Smart Home erwähnt, habe ich einen NUC (Next Unit of Computing) mit Proxmox aufgesetzt. Das ist eine Virtualisierungsplattform; auf einem einzigen Mini-PC kann ich mehrere isolierte Anwendungen betreiben.
Paperless-ngx läuft dort als ein Container. Genau wie Home Assistant, Datenbanken oder andere Anwendungen. Sie beeinflussen sich nicht gegenseitig.
Was Paperless-ngx braucht
Die Anforderungen sind nicht besonders hoch:
- CPU: Nicht besonders anspruchsvoll. Ein moderner Prozessor (wie im NUC i5) reicht locker aus.
- RAM: 2-4 GB sollten ausreichen. Je nachdem, wie viele Dokumente parallel verarbeitet werden.
- Speicher: Das ist der wichtigere Faktor. Je nach Dokumentenmenge können das schnell mehrere Hundert GB bis TB sein. Ich habe 1 TB NVMe für diesen Zweck reserviert.
- Datenbank: Paperless-ngx braucht eine PostgreSQL-Datenbank. Auch das läuft bei mir als Container.
Der Vorteil dieser Infrastruktur: Wenn ich Paperless-ngx neu installieren oder aktualisieren muss, kann ich den Container einfach neu starten. Andere Anwendungen sind nicht betroffen. Das reduziert das Risiko erheblich.
Installation und erste Konfiguration
Die Installation selbst ist relativ straightforward. Ich nutze Docker-Compose auf meinem Proxmox-System.
Die Schritte
- Container-Image herunterladen (offizielles Paperless-ngx Image)
- Datenbank (PostgreSQL) konfigurieren
- Speicherplatz zuweisen (für die Dokumentensammlung)
- Container starten
- Web-Interface öffnen und initiale Einrichtung vornehmen (Admin-Benutzer erstellen, Netzwerk-Zugang konfigurieren)
Konfiguration im Detail
Nach dem Start öffne ich das Web-Interface von Paperless-ngx. Hier muss ich einige grundlegende Einstellungen vornehmen:
- Benutzer: Einen Admin-Benutzer erstellen
- OCR-Engine: Tesseract konfigurieren (das OCR-System, das gescannte Dokumente durchsuchbar macht)
- Netzwerk-Zugang: Sicherstellen, dass ich von meinen Geräten im Heimnetz auf Paperless zugreifen kann
- Speicher-Pfade: Bestimmte Ordner für Input, Archive und Logdateien definieren
Das ist nicht kompliziert, aber es braucht Zeit, um alle Optionen zu verstehen. Die Community ist hilfreiche und bietet viele Tutorials, das hat mir bei den ersten Schritten geholfen.
Die 3 Input-Wege in der Praxis
Hier wird Paperless praktisch. Es gibt drei Wege, Dokumente ins System zu bekommen. Je nachdem, wo das Dokument herkommt, nutze ich den passenden Weg.
Input-Weg 1: Web-Upload
Das einfachste. Ich öffne das Paperless-Web-Interface und lade ein Dokument hoch.
Wie es funktioniert:
- Paperless-Interface öffnen
- Upload-Button klicken
- Datei aussuchen
- Upload läuft, Dokument wird sofort erfasst
- OCR startet im Hintergrund
Wann ich das nutze: Einzelne Dokumente, die gerade in meiner Hand sind. Schnelle Uploads zwischendurch. Wenn ich sofort nach dem Upload Schlagworte setzen möchte.
Praktisches Beispiel: Eine Rechnung kommt per Mail an, ich lade sie hoch, setze das Schlagwort "Rechnung" und die Kategorie "Internet-Provider"; fertig.
Input-Weg 2: SMB-Netzwerk-Ordner
Das ist mein Favorit für Batch-Processing. Ein einfacher Netzwerkordner, den ich von jedem Gerät im Heimnetz aus ansprechen kann.
Wie es funktioniert:
- Ich richte einen SMB-Share (Netzwerkordner) auf meinem NUC ein
- Dieser Ordner ist mit Paperless verbunden
- Ich lege Dokumente in diesen Ordner, egal von welchem Gerät im Netz
- Paperless übernimmt die Dokumente automatisch und verarbeitet sie
- Die Dokumente verschwinden aus dem Ordner und landen im Archiv
Wann ich das nutze: Mehrere Dokumente auf einmal. Batch-Processing von gescannten Dokumenten. Automatisierte Dateien-Übergaben (z.B. von einem Scanner direkt in den Ordner).
Praktisches Beispiel: Ich habe einen Papierstapel Steuerdokumente aus diesem Jahr. Ich scanne sie alle mit meinem Scanner in einen lokalen Ordner. Dann kopiere ich alle PDFs in den Paperless-SMB-Ordner. Paperless importiert sie automatisch. Keine manuellen Uploads nötig.
Input-Weg 3: Email-Empfang
Die elegante Lösung für automatisierte Prozesse und mein Favorit für spontane Uploads unterwegs.
Wie es funktioniert:
- Ich richte einen speziellen Email-Account auf meinem Mail-Server ein
- Paperless überwacht diesen Account
- Alle Emails, die an diese Adresse gehen, werden als Anhänge extrahiert
- Die Anhänge landen automatisch in Paperless
- Emails werden gelöscht (optional)
Wann ich das nutze: Rechnungen und Quittungen, die mir per Email zugesendet werden. Automatisierte Prozesse (z.B. mein Online-Banking sendet mir Kontoauszüge). Dokumente von externen Systemen. Aber auch: Spontane Uploads unterwegs. Wenn ich irgendwo bin und ein wichtiges Dokument habe, kann ich es direkt an die Paperless-Email schicken, egal wo ich bin.
Praktische Beispiele: Mein Stromanbieter sendet mir monatlich die Rechnung per Mail. Ich richte eine Weiterleitung ein, die diese Emails an meinen Paperless-Account schickt. Die Rechnungen landen automatisch in Paperless. Oder: Ich bin beim Zahnarzt, erhalte eine Quittung und mache schnell ein Foto. Das Bild schicke ich per Mail an Paperless; fertig. Wenn ich später nach Zahnarzt-Rechnungen suche, ist sie bereits im System.
Automatisierung: OCR, Tagging, Suche
Nachdem ein Dokument in Paperless angekommen ist, passiert einiges automatisch im Hintergrund.
OCR-Verarbeitung
OCR steht für "Optical Character Recognition", optische Zeichenerkennung. Gescannte Dokumente sind eigentlich nur Bilder. Ohne OCR könnte man darin nicht suchen.
Paperless nutzt Tesseract, eine Open Source OCR-Engine. Wenn ich ein Dokument hochlade (egal ob PDF oder Bild), läuft die OCR im Hintergrund. Nach ein paar Sekunden oder Minuten (je nach Dokumentengröße) ist das Dokument vollständig durchsuchbar.
Das heißt: Wenn ich "Stromrechnung Januar 2023" suche, und das Wort in einem gescannten Dokument steht, wird es gefunden.
Automatische Tagging-Regeln
Ich kann automatische Regeln einrichten: "Wenn das Dokument das Wort 'Amazon' enthält, füge automatisch das Schlagwort 'Online-Shopping' hinzu."
Das spart Zeit. Nicht jedes Dokument muss ich manuell taggen.
Dokumententypen und Kategorien
Paperless kann automatisch erkennen, ob etwas eine Rechnung, ein Vertrag oder eine Quittung ist. Das ist nicht 100% zuverlässig, aber hilft bei der Kategorisierung. Zusätzlich kann ich manuell Kategorien erstellen: "Versicherungen", "Verträge", "Finanzen", "Steuern" und Dokumente entsprechend zuordnen.
Die Suchfunktion
Das Wichtigste: Die Suche. Ich kann nach Schlagworten suchen, nach Datum, nach Dokumenttyp. Oder einfach nach Keywords z.B. "Versicherung" und bekomme alle Versicherungsdokumente angezeigt. Die Volltextsuche bedeutet: Auch wenn ich nur ein Wort aus einem gescannten Dokument kenne, finde ich es.
Praktische Anwendungsfälle aus meinem Alltag
Theorie ist gut. Aber wie nutze ich das praktisch?
Anwendungsfall 1: Steuerdokumente organisieren
Steuererklärungen sind ein großes Thema. Finanzamt, Nachweise, Quittungen.
Früher: Ich hatte einen Ordner "Steuern 2023" mit vielen Dateien. Wenn ich eine bestimmte Quittung brauche, muss ich manuell durch alle Dateien gehen.
Jetzt: Alle Steuerdokumente landen in Paperless. Mit Schlagworten wie "Steuern", "2023", "Quittung", "Berufliches". Ich suche "Steuern 2023 Telekommunikation" und bekomme sofort die relevanten Dokumente.
Die Zeitersparnis ist spürbar. Statt 10 Minuten Suchen, finde ich das Dokument in 10 Sekunden.
Anwendungsfall 2: Vertragsunterlagen archivieren
Versicherungen, Mietverträge, Lizenzen, alle Verträge landen in Paperless.
Mit Schlagworten wie "Vertrag", "Versicherung", "Krankenversicherung" kann ich schnell finden, was ich brauche. Zusätzlich nutze ich die Datums-Funktion: Ich sehe, wann Verträge erneuert werden müssen.
Anwendungsfall 3: Finanzielle Belege sammeln
Rechnungen, Quittungen, Bankabzüge, alles landet automatisch (über Email oder SMB-Ordner) in Paperless.
Mit Kategorisierung "Geschäftlich" und "Privat" habe ich eine vollständige Übersicht über meine Ausgaben. Wenn der Steuerberater fragt, kann ich schnell die benötigten Belege zusammenstellen.
Anwendungsfall 4: Behördenakten sichern
Ämter-Schreiben sind wichtig. Ich lagere sie in Paperless ein.
Mit Schlagworten wie "Behörde", "Finanzamt", "Rentenversicherung" finde ich schnell, was ich brauche, wenn es nötig ist. Eine zentrale Stelle für all diese wichtigen Dokumente.
Fazit: Der Perspektivwechsel
Technisch gesehen habe ich gelernt: Wie ein Document Management System funktioniert. Wie OCR Dokumente durchsuchbar macht. Wie man Prozesse automatisiert. Wie man in großen Dokumentenmengen schnell findet, was man braucht.
Aber die wichtigere Erkenntnis ist eine andere.
Früher dachte ich: "Meine Dokumente müssen irgendwo sicher abgelegt sein; das ist genug."
Jetzt denke ich: "Meine Dokumente sollen sicher, organisiert UND auffindbar sein."
Das ist ein großer Unterschied. Es geht nicht nur um Speicherung; es geht um Nutzung.
Und das ist der Homo Creator-Ansatz, den ich interessant finde: Ich habe mein eigenes System gebaut. Nicht weil ich alles über Dokumentenverwaltung wusste, sondern weil ich bereit war, die einzelnen Teile zu lernen und sie zusammenzusetzen.
Das hat sich auch auf andere Bereiche ausgeweitet. Wenn Paperless-ngx läuft, warum nicht auch andere selbstgehostete Anwendungen? Die eine oder andere Idee habe ich noch.
Das ist, was mich reizt: Nicht abhängig sein von Cloud-Anbietern. Nicht abhängig sein von ihren Geschäftsentscheidungen. Stattdessen: Eigenes System, eigene Regeln, vollständige Kontrolle.
Papierloses Leben ist möglich. Und es ist nicht so kompliziert, wie es klingt.

- Details
- Geschrieben von: Moritz Conjé
- Kategorie: Work-Life-Flow
- Zugriffe: 672
Einleitung: Die Ausgangslage
Home-Automation war lange ein Konzept, mit dem ich mich nicht auseinandersetzt habe. Bis Arbeitskollegen anfingen, davon zu erzählen.
Diese Gespräche waren informativ und detailliert - erzeugten bei mir aber auch eine erste Hürde: zu viel Komplexität, zu viel spezialisiertes Wissen erforderlich. Mein erster Gedanke: „Das ist für mich wahrscheinlich zu viel."
Dann kam eine längere Recherchephase. Verschiedene Systeme, ihre Ansätze, ihre Vor- und Nachteile. Dabei wurde mir ein zentrales Problem deutlich: Die meisten Systeme sind cloudbasiert. Deine Daten liegen auf Servern eines Anbieters. Du nutzt das System, aber kontrollierst nicht, wo und wie deine Daten gespeichert werden.
Das hat mich bewogen, eine andere Route zu suchen: Open Source. Systeme, deren Code offen einsehbar ist. Systeme, bei denen ich die Kontrolle über meine Daten behalte und sie lokal betreiben kann.
Diese Suche führte mich zu Home Assistant.
Die erste Hürde: Hardware und Virtualisierung
Hardware-Entscheidungen
Der erste konkrete Schritt: Welche Hardware brauche ich?
Ein vollwertiger PC mit Monitor kam nicht in Frage. Ein Mini-PC - ein NUC (Next Unit of Computing) - schien die richtige Größe zu sein. Die Auswahl war aber größer als erwartet: Prozessoren, RAM, Stromverbrauch, Preis.
Die Lösung als günstiger Einstieg war ein NUCi5 von Kleinzeigen mit den Specs:
- Intel(R) Core(TM) i5-7260U CPU @ 2.20GHz
- 8GB RAM
- 1 TB NVMe
Dazu kam ein strategischer Überlegung: In Zukunft könnte ich weitere Projekte auf diesem System umsetzen wollen. Ein Dateiserver. Andere selbstgehostete Anwendungen.
Das führte zu der Frage: Wie isoliere ich verschiedene Projekte voneinander? Wie verhindere ich, dass ein Update in einer Anwendung die anderen beeinträchtigt?
Diese Frage führte mich zu Virtualisierung - ein Konzept, das ich aus beruflicher IT-Welt kannte, aber noch nie selbst angewendet hatte.
Proxmox als Virtualisierungslösung
Ich recherchierte verschiedene Virtualisierungslösungen und stieß auf Proxmox - eine Open Source Virtualisierungsplattform mit großer Community.
Proxmox ermöglicht es, auf einem einzigen NUC mehrere isolierte Umgebungen zu schaffen. Jede Anwendung läuft in ihrem eigenen Container. Sie beeinflussen sich nicht gegenseitig.
Damit war klar: Ich baue nicht einfach nur eine Anwendung. Ich schaffe eine Infrastruktur - die Basis, auf der ich in Zukunft weitere Projekte umsetzen kann.
Der praktische Vorteil dieser Isolation: Sollte es bei einer Anwendung Probleme geben, kann ich diese neu aufsetzen, ohne dass andere Systeme davon betroffen sind. Das reduziert das Risiko erheblich und half mir bereits bei der initialen Instalation, die nicht gleich klappte.
Praktische Umsetzung
Die nächsten Schritte waren praktischer Natur: NUC ins Heimnetzwerk integrieren. Sicherstellen, dass Home Assistant stabil erreichbar ist. Entscheiden, welche Ports geöffnet werden.
Das waren keine großen technischen Hürden, aber eine Reihe von Details, die ich selbst recherchieren musste.
Das ist ein wichtiger Punkt: Man muss nicht alles im voraus wissen. Man muss bereit sein, die einzelnen Schritte zu gehen und Fragen zu stellen.
Das erste funktionierende System: Daten sammeln und visualisieren
Das Problem: Daten ohne Kontext
Home Assistant war installiert, der NUC lief. Aber jetzt?
Home Assistant allein ist eine Verwaltungsoberfläche. Sie braucht Daten, um sinnvoll zu sein. Und sie braucht eine Möglichkeit, diese Daten verständlich zu machen.
Ich installierte InfluxDB - eine Datenbank, die spezialisiert auf Sensordaten ist. Hier landen alle Messwerte strukturiert mit Zeitstempel: Temperatur, Luftfeuchte, Energieverbrauch.
Dann installierte ich Grafana - ein Visualisierungstool, das diese Rohdaten in Graphen umwandelt.
Die Visualisierung ändert alles
InfluxDB speichert Daten, Grafana holt sie sich und visualisiert sie. Ich musste mich eine Weile mit den Variablen und "Verarbeitungsoptionen" von Grafana beschäftigen. Doch nach einer Weile sah ich auf meinem Bildschirm nicht nur Tabellen mit Zahlen - ich sah Kurven, Muster, Zusammenhänge.
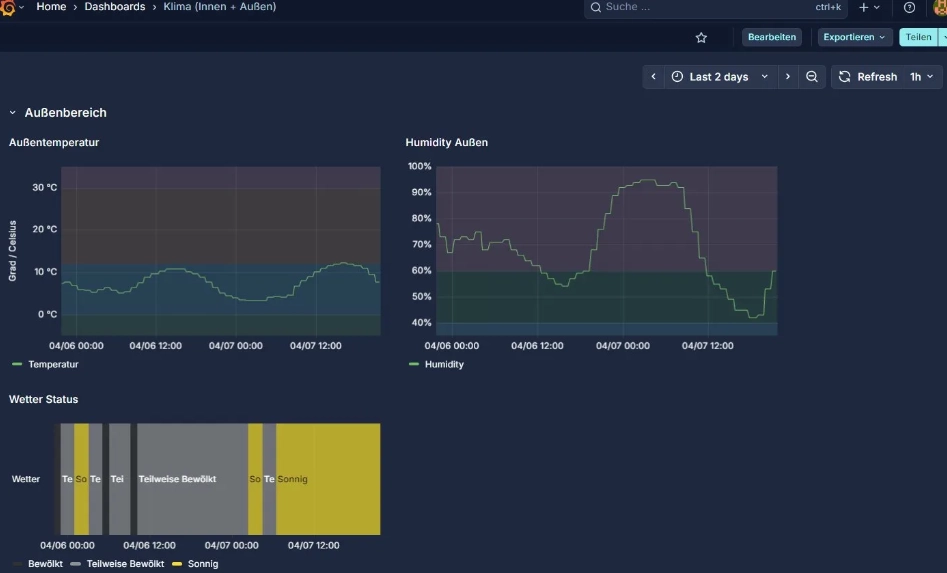
Ich konnte sehen, wie die Temperatur im Schlafzimmer über den Tagesverlauf reagiert. Wie die Luftfeuchte auf Wetterverhältnisse antwortet. Wie sich nachts die Außentemperatur auf die Innentemperatur auswirkt.
An diesem Punkt war mein initiales Ziel erreicht: Sensoren liefern Daten. Eine Datenbank speichert sie. Ein Visualisierungstool zeigt sie mir und ich konnte die äußeren lokalen Klimadaten mit den Messwerten meiner Wohnung verknüpfen.
Optimierung der Datenquellen
Das erste Problem: Datenqualität
Die ersten Sensoren, die ich einband, waren meine bestehenden Temperatur- und Luftfeuchtigkeitssensoren. Ein BLE-Empfänger auf einem ESP32-Mikrocontroller sammelte diese Daten. Ich bestellte eine handvoll Controller ukd lernte, wie man sie mit der entsprechenden Software flasht. Danach bekamen die nackten Sensoren noch ein schlichtes Gehäuse und wurde an neuralgischen Punkten in der Wohnung verteilt.
Technisch funktionierte alles. Aber die Datenqualität war suboptimal:
- Die Sensoren sende alle paar Sekunden einen Wert → Das erzeugt Rauschen in den Graphen
- Ein anderer Sensor zeigte vier Dezimalstellen an → Mehr Genauigkeit als nötig
- Die Sensor-Namen waren kryptisch →
sensor_5a8fstatt aussagekräftigen Namen
Die Daten waren vorhanden, aber nicht optimiert.
Template-Sensoren als Lösung
Template-Sensoren schafften Abhilfe. Ein Template-Sensor ist ein virtueller Sensor, den ich selbst definiere, basierend auf echten Sensoren.
Mit Template-Sensoren kann ich:
- Die Datenrate reduzieren (nur jeden 5. Wert speichern statt alle paar Sekunden)
- Die Messgenauigkeit anpassen (auf zwei Dezimalstellen runden)
- Aussagekräftige Namen vergeben (sensor_wohnzimmer_temperatur statt sensor_5a8f)
- Korrekturberechnungen durchführen (z.B. eine fehlerhafte Messung korrigieren)
Das war ein wichtiger Lernpunkt: es kommt nicht auf die Masse an Daten an, sondern auf die Qualität.
Erweiterung: Kontext und Kontrolle
Kontext durch externe Daten
Mit den Basis-Sensoren wollte ich das System erweitern. Ich integrierte Wetterdaten von Met.no über einen Template-Sensor, der eine API anzapft.
Plötzlich hatte ich nicht nur Daten aus meinem Zuhause, sondern auch Kontext der Außenwelt.
Das macht einen Unterschied: Wenn die Innentemperatur sinkt, kann ich jetzt sehen, ob das an der Außentemperatur liegt oder an meinen Verhaltensweisen (Fenster offen).
Kontrolle durch Aktoren
Dann kam der nächste Schritt: der Sonoff Zigbee-Stick. Damit konnte ich Matter-kompatible Geräte einbinden - nicht nur Sensoren, sondern auch Schalter und Mess-Steckdosen:
- Mess-Steckdosen (um Stromverbrauch zu messen)
- Schaltsteckdosen (um Geräte zu schalten)
Das System wurde damit von einer reinen Beobachtungslösung zu einer aktiven Infrastruktur, die auf ihre Umgebung reagieren kann.
Was sich durch dieses Projekt geöffnet hat
Die technische Seite
Ich habe gelernt, wie Virtualisierung funktioniert. Wie Datenbanken und Visualisierungswerkzeuge zusammenarbeiten. Wie man Sensoren einbindet. Wie man Systeme isoliert und wartet.
Der Perspektivwechsel
Aber die wichtigere Erkenntnis ist eine andere: Ich bin kein reiner Konsument mehr.
Früher: „Mein Smart Home müssen andere bauen. Ich zahle, sie installieren, ich nutze."
Jetzt: „Ich baue das selbst. Nicht als Profi. Aber als jemand, der bereit ist, die einzelnen Schritte zu lernen und sie zusammenzusetzen."
Das hat sich auch auf andere Bereiche ausgeweitet. Virtualisierung war ein abstraktes Konzept. Jetzt habe ich es umgesetzt. Ich verstehe das Grundkonzept und sehe das Potenzial für weitere Projekte. Das ist nicht mehr Theorie - das ist nun Erfahrung.
Und es hat zu neuen Ideen geführt: Wenn ich Home Assistant aufgesetzt habe, warum nicht auch andere selbstgehostete Anwendungen? Ein Dateiserver. Ein Paperless-System für Dokumentenverwaltung. Alles auf der gleichen Infrastruktur, alles isoliert, alles unter meiner Kontrolle.
Das reizt mich am Homo Creator-Ansatz: nicht als Fertig-Experte starten, sondern als jemand, der willens ist, die einzelnen Teile zu lernen und sie zusammenzusetzen.
Ausblick: Der nächste Schritt
Bis hier habe ich ein System, das beobachtet, speichert und visualisiert. Das funktioniert und ist wertvoll.
Der nächste logische Schritt sind Automationen:
- Wenn die Temperatur sinkt, soll die Heizung reagieren
- Wenn die Luftfeuchte kritisch wird, soll eine Benachrichtigung erfolgen
- Wenn die Sonne untergeht, sollen die Lichter angehen
- Wenn ich nicht zuhause bin, sollen Sicherheitsfunktionen aktivieren
Das ist der Punkt, wo ein Smart Home von einer Messlösung zu einem reaktiven System wird.
Aber auch diesen Schritt freue ich mich, an der Umsetzung der einzelnen Komponenten zu lernen.